Wie funktioniert JavaScript?
JavaScript hat eine Single-Thread-Beschaffenheit. Es kann jeweils nur eine Aufgabe ausgeführt werden. Das heißt, dass Code nacheinander – also sequentiell – ausgeführt wird. Bis der gesamte Prozess (also die Aufgabe oder Operation) ausgeführt wurde, wird der Thread nicht gestoppt oder aufgehalten. Im Gegensatz dazu gibt es aber auch Multi-Thread-Sprachen. Hier können mehrere Prozesse auf verschiedenen Threads gleichzeitig ablaufen, ohne dass sie sich gegenseitig blockieren.
Betrachten wir zum Thema “Single-Thread-Beschaffenheit” folgenden Code. 2 Funktionen werden definiert und aufgerufen:
let printOne = function() {
console.log("Hallo 1");
}
let printTwo = function() {
console.log("Hallo 2");
}
printOne();
printTwo();
Die Ausgabe wäre dann wie folgt:
Hallo 1
Hallo 2
Manchmal kann das aber zum Problem werden. Bei diesem einfachen Code zwar nicht, aber stell dir vor beide Funktionen würden mehr Arbeit leisten. Was wenn nun Funktion 1 20, 30 oder sogar 40 Sekunden braucht um fertig ausgeführt zu werden? Da JavaScript im Haupt-Thread des Browsers läuft, müsste alles andere warten bis die Funktion fertig ist. Auch müsste Funktion 2 lange warten, bis sie drankommt und ausgeführt wird. Hier spricht man dann auch von Blockierung. Heutzutage unvorstellbar, da kein Nutzer so lange auf eine Website wartet.
Zum Glück gibt es Web APIs. Dazu gehören z.B.:
- setTimeout
- HTTP-Requests
- DOM API
- und so weiter
Wie in meinem Beitrag zu Callback-Funktionen erklärt können diese helfen, dass Code asynchron – also nicht-blockierend – ablaufen kann. Wie läuft das ab? Über den Event-Loop bzw. über die Ereignisschleife.
Wie funktioniert der Event-Loop?
Zunächst gibt es einen Code:
Der Code wird nun von oben nach unten abgearbeitet:
Hier werden 2 Funktionen definiert und weiter unten aufgerufen. Sobald die Funktion aufgerufen wird, kommt sie in den Call-Stack (ein Teil der JavaScript-Engine). Der Call-Stack funktioniert dabei nach dem LIFO-Prinzip. Am Beispiel der ersten Funktion, die aufgerufen wird (print), sieht das wie folgt aus:
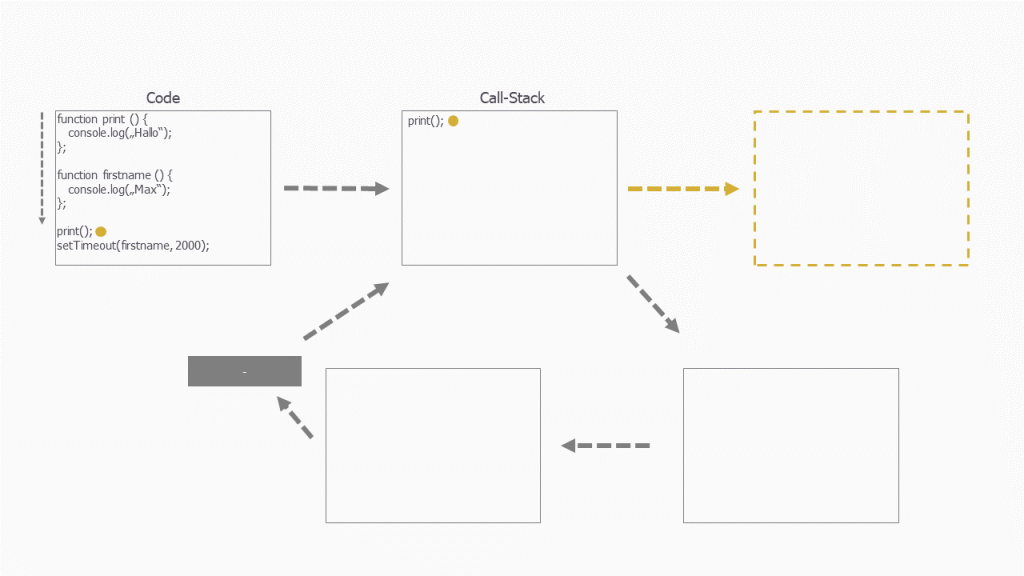
Und sobald die Funktion etwas zurückgibt, wird sie auch sofort ausgegeben:

Im nächsten Schritt kommt die Funktion firstname() dran. Diese wird jedoch mit einem setTimeout() ausgeführt. Auch hier wandern die Funktionen zunächst immer in den Call-Stack:
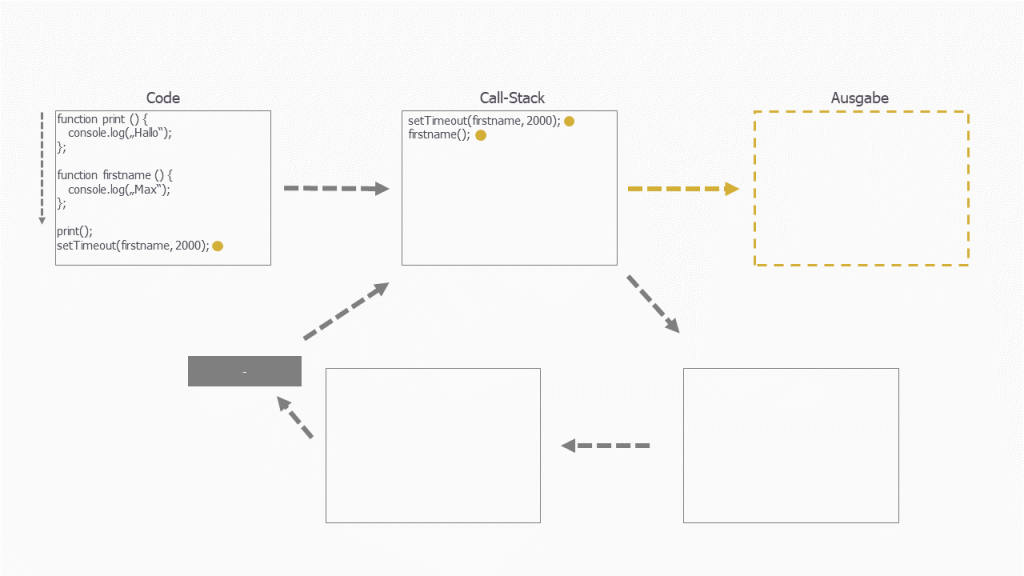
Die setTimout-Funktion wird uns durch die Web API zur Verfügung gestellt. Mit dieser Funktion können wir die Ausführung einer Funktion hinauszögern, ohne dass es den Haupt-Thread blockt. Aus diesem Grund übernimmt ab hier zunächst einmal die Web API. Gleichzeitig verschwinden die Funktionsaufrufe aus dem Call-Stack:

In der Web API läuft nun ein Timer. Die Laufdauer hängt vom Wert ab, den wir bei der setTimeout-Funktion mitgegeben haben. In unserem Fall wären das 2 Sekunden:

Wenn der Timer abgelaufen ist, dann kommt der Callback nicht direkt zurück in den Call-Stack, sondern zuerst in die Callback-Warteschlange (Queue):

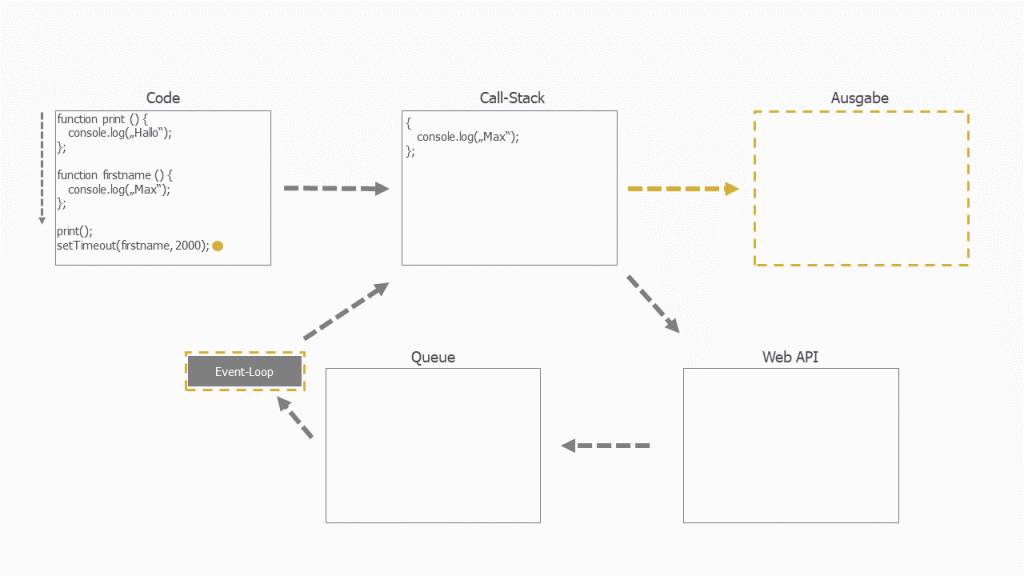
Und wie man an der Grafik sehen kann ist noch eine Stelle zwischen Warteschlange und Call-Stack vorhanden. Sprich: Selbst wenn der Timer abgelaufen ist und die Callback-Funktion dadurch aus der Web API in die Warteschlange wandert, heißt das nicht, dass die Funktion dann sofort in den Call-Stack geht um direkt ausgeführt zu werden. An dieser Stelle handelt es sich um eine Warteschlange (!). Heißt: Die Callback-Funktion muss noch warten. Und hier kommt dann der Event-Loop ins Spiel:

Der Event-Loop stellt die Verbindung zwischen Warteschlange und Call-Stack her. Grundsätzlich ist es so, dass der Event-Loop den Code, der in der Warteschlange an erster bzw. oberster Stelle steht, zuerst in den Call-Stack wirft. Jedoch kann es sein, dass im Call-Stack schon Funktionen aufgerufen worden sind und gerade verarbeitet werden. Der Event-Loop wartet dabei, bis der Call-Stack leer ist und fügt erst dann den Code aus der Warteschlange hinzu:
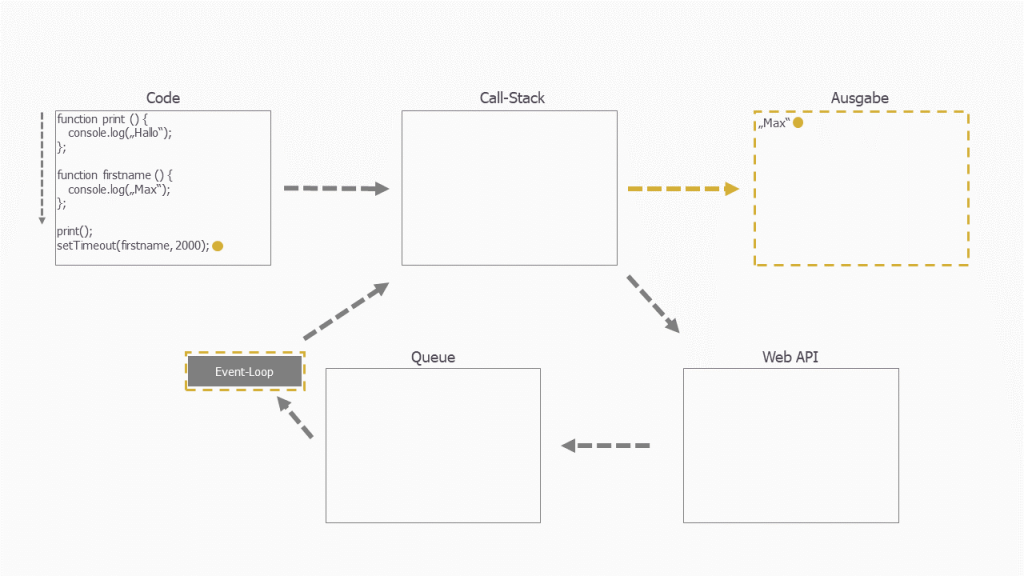
Zum Schluss wird die Funktion ausgeführt und der Wert wird ausgegeben:
Noch eine Code-Analyse
Um das Prinzip nochmal besser zu verstehen, schaue wir folgenden Code an:
console.log("Erster");
setTimeout(() => {
console.log("Zweiter");
}, 2000);
console.log("Dritter");
Aufgrund der Single-Thread-Beschaffenheit führt JavaScript den Code nacheinander – also sequentiell oder synchron – aus. Im Code sehen wir, dass 3 Strings in die Konsole geloggt werden. Nun könnte man davon ausgehen, dass nach der Ausführung des Codes folgendes in der Konsole steht:
Erster
Zweiter
Dritter
Das ist falsch. Richtig wäre:
Erster
Dritter
Zweiter
Der Ausführungsprozess wartet nicht auf den setTimeout-Code, um dann erst “Dritter” auszugeben. Und genau hier sieht man, dass neben dem einen Thread (Stichwort “Single-Thread-Beschaffenheit”) ein weiterer Thread hier nachgeholfen hat, um eine asynchrone Ausführung zu gewährleisten. Diese asynchrone Ausführung wird clientseitig von Browsern durch Web APIs zur Verfügung gestellt: Events, Timer, AJAX, etc. Und wie wir oben gesehen haben, kümmert sich die Web API darum, dass der Code über die Warteschlange zum Event-Loop übergeben wird, der wiederum Sorge dafür trägt, dass der Code wieder zurück in den Call-Stack kommt.