- Was ist JavaScript und wie funktioniert es?
- Crawling und Indexierung von JavaScript-Inhalten durch Googlebot
- JavaScript SEO: Google vs. Rest
- Wann ist “JavaScript SEO” relevant?
- Worauf aus SEO-Sicht beim Einsatz von JavaScript zu achten ist
- JavaScript-Audit
- Weitere Informationen zum Thema JavaScript und SEO
- Offizielle Statements seitens Google zu JavaScript
- SEO-JavaScript-Tests in der Praxis
Was ist JavaScript und wie funktioniert es?
JavaScript (Abgekürzt: JS) ist eine Skriptsprache für Webseiten, die dynamisch ist. Mit JS lassen sich Inhalte, Content und Design ereignisgesteuert ändern. Aufgabe von JS ist es, auf Benutzereingaben zu reagieren. Während also HTML und CSS dem Browser mitteilen, wo ein Element liegt und wie es aussehen soll, kann man mittels JS dynamische Funktionen wie Animationen oder Eingabekontrollen bei Formularen einsetzen.
Dabei wird JS meist nicht auf dem Server ausgeführt, sondern direkt auf dem Computer des Nutzers. Daher spricht man bei JS auch von einer clientseitigen Programmiersprache. Bei der Ausführung von JS wird zwar das gegenwärtig angezeigte HTML-Dokument geändert, diese Änderungen passieren aber nur auf Clientseite (im Arbeitsspeicher des Computers). Das eigentliche HTML-Dokument, welches auf dem Server liegt, bleibt dabei unverändert.
Das heißt für uns, dass sich das HTML-Dokument ändern kann, ohne das ein neuer Request vom Server benötigt wird. Die Veränderung im HTML-Dokument kann man im DOM (Document Object Model) sehen. Das DOM einer Seite kann sich demnach vom Quellcode unterscheiden.
Genauer gesagt funktioniert JavaScript folgendermaßen:
- Anfrage: Der Browser fordert das HTML-Dokument beim Server an.
- DOM-Erstellung: Der Browser fängt an das DOM zu erstellen.
- 1. Event “DOMContentLoaded”: Während der Browser arbeitet, werden verschiedene Events abgefeuert. DOMContentLoaded ist das Erste. Dieses bedeutet, dass das HTML-Dokument geparst und geladen wurde. Der Browser ist nun bereit JavaScript auszuführen.
- Ausführung von JavaScript: Nun wird das JavaScript ausgeführt, welches Änderungen am Dokument vollziehen kann. Ab hier schaut der Quellcode der Seite anders aus als das DOM.
- 2. Event “Load Event”: Dieses Event wird abgefeuert, wenn alle Ressourcen des Dokuments geladen wurden und bedeutet soviel wie: Die Seite ist fertig!
- Weitere Events: Ab nun können weitere Events folgen, wie zum Beispiel User Events, die die Seite weiter verändern können.
Bei Schritt 4 und 6 kann viel JavaScript im Browser ausgeführt werden. Genau hier haben viele Crawler Probleme. Sprich, Suchmaschinenbots müssen die Arbeit von einem Browser übernehmen, damit JS-Inhalte gecrawlt und gerendert werden können. Dazu gehören alle Technologien und Ressourcen sowie eine Rendering-Engine. Dies bedeutet jedoch einen deutlichen Mehraufwand für Suchmaschinen.
Crawling und Indexierung von JavaScript-Inhalten durch Googlebot
Bevor wir uns direkt mit der JavaScript-Indexierung von Inhalten auseinandersetzen, müssen wir zunächst verstehen, wie Google grundsätzlich Websites crawlt und indexiert. Für normale HTML-Seiten sieht der Prozess grob wie folgt aus:
- Scheduler: Bevor der Crawler losstartet wird der Crawl seitens Google geplant.
- Crawler: Der Crawler besucht zunächst die Website und verarbeitet das Dokument. Das Dokument wird dann an den Parser übergeben.
- Parser: Hier wird die Seite in die relevanten Bestandteile zerlegt, bevor sie an den Indexer gehen. Links werden entnommen und es werden weitere URLs gecrawlt und CSS-Dateien werden heruntergeladen. Es werden zudem alle URLs an Caffeine (= Indexer) übergeben.
- Indexer: Das übergebene Dokument erfasst nun der Indexer. An diesem Zeitpunkt wird der Inhalt indexiert und ist somit im Google-Index.
Werden im Dokument weitere Links identifiziert, dann wandern diese zurück zum Scheduler. Der Scheduler plant das Crawling, übergibt den Links an den Crawler. Dieser ruft den Link auf, verarbeitet den Inhalt und schickt das Dokument über den Parser an den Indexer, der es nun wieder indexieren kann. Der Kreislauf schließt sich also (hier vereinfacht ohne Scheduler und Parser dargestellt):
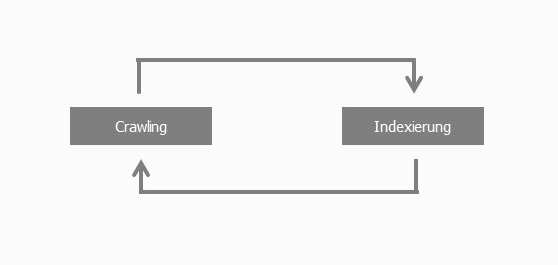
Kommt nun JavaScript ins Spiel – also wenn der komplette Inhalt einer Seite oder Teile davon per JavaScript ausgespielt werden – wird eine zusätzliche Schicht benötigt: Rendering. Das Beispiel von oben würde dann wie folgt ablaufen (Änderungen sind fett markiert):
- Scheduler: Bevor der Crawler losstartet wird der Crawl seitens Google geplant.
- Crawler: Der Crawler besucht zunächst die Website und verarbeitet das Dokument. Das Dokument wird dann an den Parser übergeben.
- Parser: Hier wird die Seite in die relevanten Bestandteile zerlegt, bevor sie an den Indexer gehen. Links werden entnommen und es werden weitere URLs gecrawlt und CSS- sowie JS-Dateien werden heruntergeladen. Es werden zudem alle URLs an Caffeine (= Indexer) übergeben.
- Indexer: Das übergebene Dokument erfasst nun der Indexer. Alles was sofort indexiert werden kann (z.B. Text im HTML), wird sofort indexiert. JavaScript wandert jedoch in den Rendering-Prozess.
Visuell sieht das wie folgt aus:
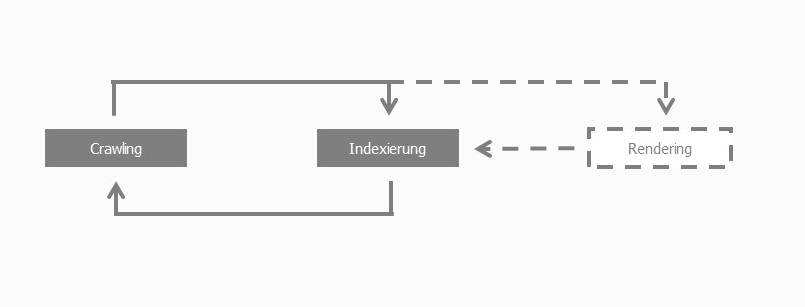
Der Bot führt das JavaScript erst dann aus, wenn die Seite sich im Rendering-Prozess befindet. Dieser Vorgang kann aber sehr rechenintensiv werden. JavaScript muss…
- …zunächst heruntergeladen werden,…
- …um im nächsten Schritt das Parsing durchzuführen und…
- …zum Schluss muss es noch ausgeführt werden.
Und dieser Vorgang kann sehr oft nicht immer sofort vom Bot durchgeführt werden. Diese Trennung von Indexierung und Rendering macht aber Sinn:
- Inhalt, der nicht per JavaScript ausgespielt wird, kann somit sofort indexiert werden.
- Inhalt, der von JavaScript abhängt, kann zu einem späteren Zeitpunkt indexiert werden.
Bei JavaScript-Inhalten heißt das also: Der Googlebot kann die JavaScript-Inhalte grundsätzlich auslesen und verarbeiten. Man muss jedoch bei der Indexierung mit längeren Wartezeiten rechnen. Bei Inhalten, die schnell zur Verfügung stehen müssen, bieten sich daher alternativ 2 Optionen an:
- Die Inhalte nicht per JavaScript ausspielen, sondern direkt im HTML mitliefern.
- Geht kein Weg an JavaScript vorbei, dann können diverse Rendering-Technologien zur Unterstützung angewandt werden (dazu später mehr).
JavaScript SEO: Google vs. Rest
Man muss immer im Hinterkopf behalten, dass der Googlebot mit der Ausführung von JavaScript sehr fortgeschritten ist, während andere Bots und Crawler das nicht so gut bzw. auch gar nicht bewerkstelligen. Auch hier bietet sich an, diverse Rendering-Techniken einzusetzen, um auch andere Bots und Crawler korrekt bedienen zu können.
Wann ist “JavaScript SEO” relevant?
Grundsätzlich gibt es 2 Typen von JavaScript auf Websites:
- JavaScript, welches das HTML und CSS mit zusätzlichen Funktionen erweitert und UX verbessert.
- JavaScript, welches benutzt wird, um den Hauptinhalt der Website auszuspielen.
Bei Fall 1 werden meist kleinere Animationen in die Website eingefügt. Aus SEO-Sicht werden solche Techniken nicht als JavaScript-Seiten bezeichnet. Solche kleinen “Addons” haben keine Auswirkungen auf SEO, da der kritische Hauptinhalt nicht betroffen ist.
Anders sieht es bei Fall 2 aus. Da hier der Hauptinhalt von JavaScript abhängt, könnte es zu Indexierungsverzögerungen kommen. Um zu überprüfen, ob man davon betroffen ist, kann man sich als grobe Faustregel folgendes merken:
- Wenn der Inhalt im HTML-Quellcode vorhanden ist, muss man sich keine Sorgen machen. Dieser Inhalt wird dann ohne JavaScript ausgespielt, wodurch Suchmaschinen diesen ganz normal indexieren können.
- Alternativ kann man auch JavaScript im Browser deaktivieren. Wenn der Hauptinhalt immer noch im Browser zu sehen ist, dann wird dieser nicht per JavaScript ausgespielt. In diesem Fall muss man sich ebenfalls keine Sorgen machen.
- Falls im HTML-Code der Hauptinhalt der Seite nicht auffindbar ist oder wenn bei ausgeschaltetem JavaScript im Browser der Hauptinhalt verschwindet, hat man es mit einer JavaScript-Seite zu tun, wo man einige Dinge beachten muss.
Wenn der Inhalt im HTML sichtbar ist, dann wird der Inhalt normal indexiert. Wenn der Inhalt nicht im HTML sichtbar ist, hat man es mit JavaScript-Inhalten zu tun. Dieser wird vom Googlebot zeitverzögert indexiert. Soll der Inhalt schneller indexiert werden, dann sollte der Inhalt entweder initial mit dem HTML geladen werden oder man verwendet eine Rendering-Technik zur statischen Bereitstellung der JavaScript-Inhalte.
Worauf aus SEO-Sicht beim Einsatz von JavaScript zu achten ist
Kommen wir zur Praxis. Nachfolgend findest du zunächst die wichtigsten Punkte kurz und knapp als Übersicht. Nach der Übersicht gehe ich auf einzelne Themen nochmal im Detail ein.
Grob zusammengefasst sollte man aus SEO-Sicht beim Einsatz von JavaScript auf folgende Aspekte achten:
- URL: Damit eine Seite in den Google-Index kommt, braucht diese eine eigene URL. Das heißt, dass bspw. Single Page Apps mit einzigartigen URLs je Screenview ausgestattet werden sollten.
- Viewport: Diese Angabe ist für das JS-Rendering wichtig. Je genauer es ist, desto schneller kann der Bot das Rendering durchführen.
- Meta-Daten: Bei JavaScript-Seiten dürfen die Meta-Daten nicht fehlen. Hierbei gilt das Gleiche wie bei HTML-Seiten: Title, Meta-Description, etc. müssen optimiert und mitgegeben werden.
- Inhalte: Inhalte, die schnell indexiert werden müssen, sollten mit dem initial ausgelieferten HTML mitgegeben werden.
- Interne Links: Damit der Googlebot internen Links folgen kann, müssen diese zur Sicherheit mit “a href” und “img src” versehen werden.
- Gleiche Versionen schaffen: Beim JS-Rendering können 2 verschiedene Versionen des Dokuments entstehen: pre-DOM and post-DOM. Achte darauf, dass beide Versionen hinsichtlich SEO-Metas einheitlich sind, um Cloaking zu vermeiden. Das HTML kann bspw. einen anderen Canonical haben als die gerenderte JavaScript-Seite. Das sollte vermieden werden.
- Bot-Beschränkungen: Zu beachten ist, dass nicht alle Bots gleichermaßen mit JavaScript umgehen können. Daher sollte man Title, Meta-Description, Tags für Social Media uns sonstige technischen SEO-Tags in den HTML-Code platzieren.
- robots.txt: JavaScript-Daten dürfen über die robots.txt nicht gesperrt sein.
- Strukturierte Daten: Bei JavaScript-Seiten empfiehlt Google den Einsatz von JSON-LD.
- Progressive Enhancement: Google empfiehlt die “Entwicklung durch schrittweise Verbesserung”. Struktur, Navigation und wichtige Inhalte sollten mittels HTML dargestellt werden. Auf dieser Basis kann dann die “Darstellung und Oberfläche mit AJAX” aufgepeppt werden. Dadurch kann der Bot die wichtigsten Informationen crawlen und verarbeiten, während Nutzer mit JS-Funktionen bedient werden können.
Zugänglichkeit
Grundvoraussetzung, dass Bots JavaScript crawlen können, ist die Freigabe dieser Ressourcen. JS-Dateien sollten demnach nicht über die robots.txt geblockt werden. Falls doch, dann können sich Suchmaschinen kein volles Bild der Webseite machen, was zu weniger Ranking-Relevanz führen kann.
Am besten blockiert man keine CSS- und JS-Dateien über die robots.txt. Aber Achtung: Vorher nochmal mit dem Entwickler-Team sprechen, ob es eventuell doch sensible Dateien gibt, auf die Bots keinen Zugriff haben dürfen. Wichtige Tools, um die Crawlbarkeit der eigenen Seite zu testen sind:
- Google Search Console “Abruf wie durch Google”
- Fetch and Render Tool von technicalseo.com
- Robots.txt Testing Tool von Screaming Frog
Interne Links
Sobald Suchmaschinenbots auf einer Seite landen, beginnen sie die komplette Seite zu crawlen und folgen dabei internen Links um von einer zur nächsten Seite zu gelangen. Dabei ist es wichtig, dass die internen Links auch als solche erkannt werden, sonst kann Google a) den Links nicht folgen und b) Linkpower nicht auf die Zielseite übertragen. Folgende Links können vom Google-Bot erfasst und verarbeitet werden:
<a href="good-link">Wird gecrawlt</a>
<a href="good-link" onclick="changePage('good-link')">Wird gecrawlt</a>
Folgende Links werden nicht gecrawlt:
<span onclick="changePage('bad-link')">Wird nicht gecrawlt</span>
<a onclick="changePage('bad-link')">Wird nicht gecrawlt</a>
In einem Tweet teilte John Müller mit, dass Google onclick-Links seltener folgt. Daher sollte man auf klassische a-href-Links setzen.
Auch erschien Ende April 2020 ein Video von Martin Splitt auf YouTube, der das Thema “Links und JavaScript” beleuchtete. Zusammengefasst die aus SEO-Sicht folgendes bei internen Links wichtig:
- Bei internen Links am besten mit ahref-Tags arbeiten. Es ist aber auch ok, wenn man Links mit JS aktualisiert oder setzt (z.B. als Attribut im a-Tag mit onclick=”goTo(‘stuff’)”).
- Das ahref-Attribut sollte auf keinen Fall ausgelassen werden.
- Innerhalb des ahref-Attributs sollten keine Pseudo-URLs geschrieben werden wie z.B. href=”javascript:goTo(‘stuff’)”.
- Buttons sollten als interne Links nicht genutzt werden. Wenn bei Klick auf den Button auf der Seite selbst was verändert wird, dann sind Buttons in Ordnung.
- Interne Links sollten nicht von click-Event-Handler abhängen.
- Es sollten grundsätzlich semantisches HTML zum Einsatz kommen und es sollte auf “richtige” URLs verwiesen werden. Als “richtige” URLs werden traditionelle URLs wie domain.com/seite/ sowie (optional) Fragment-URLs wie domain.com/seite#unterkategorie verstanden. Bei Fragment-URLs sollte man nur im Hinterkopf behalten, dass sie nicht gecrawlt werden.
Einen Tipp nannte auch Google, wie man auf JS-Seiten Links testen kann. Diese sollte man versuchen in einem neuen Tab im Browserfenster zu öffnen. Öffnen die Links, dann wird dies aus SEO-Sicht mit großer Wahrscheinlichkeit auch für den Googlebot passen. Andersrum – wenn der Link nicht öffnet – dann wird der Bot ebenfalls damit Probleme haben können.
Hinsichtlich Links sollte man bei der Backlink-Analyse folgende berücksichtigen: Viele Linkaudit-Tools sind noch nicht in der Lage, JavaScript-Links auszulesen und sie in die Daten mit aufzunehmen. Daher lohnt sich hier auch ein Blick in die Google Search Console, wo Google solche Art von Links mit aufführt. Nachteil: Die Google Search Console gibt hier nur maximal 1000 Datensätze aus. Aber besser als nichts!
URLs
Nachdem Google über die robots.txt feststellt, dass er JS-Dateien crawlen darf und auf interne Links stößt, um auf weitere Seiten zu kommen, landet er zunächst mal auf einer URL und muss nun damit ebenfalls umgehen können. Dabei gibt es unterschiedliche Methoden wie man eine URL ausliefern kann:
- Traditionell: Standard-URLs wie beispiel.com/seite/ können von Bots gecrawlt und indexiert werden. Zu den traditionellen URLs gehören auch Sprungmarken wie beispiel.com/seite#unterbereich, die auf einen bestimmten Block innerhalb der Seite verweisen. Sprungmarken-URLs werden von Google ignoriert; sprich solche URLs landen nicht im Index.
- Hash (#): Irgendwann kam AJAX und man konnte mittels JavaScript Content vom Server abfragen und darstellen, ohne die Seite komplett neu laden zu müssen. Um aber auch innerhalb der Seite navigieren zu können und die Browser-Historie zu speichern, hat man Fragment Identifier eingesetzt, um auch Deep-Linking zu ermöglichen. Eine URL mit Inhalten sah dann so aus: beispiel.com/#seite. Nun hat man also das Hash für 2 Zwecke verwendet: Für Sprungmarken und JS-Seiten. Google kann hier also nicht unterscheiden, wofür das Hash tatsächlich eingesetzt wird. Dementsprechend können solche URLs nicht indexiert werden.
- Hashbang (#!): Deshalb führte man Hashbang-URLs zu besseren Unterscheidung ein: beispiel.com/#!seite. 2009 empfahl Google Hashbang-URLs (z.B. beispiel.de/page?query#!key=value) mit “_escaped_fragment_=” crawlbar zu machen. Dadurch konnten AJAX-Inhalte indexiert werden. In einem Webmaster-Hangout hat jedoch John Müller mitgeteilt, dass man auf Hashbang-URLs zurückgreifen wolle (also beispiel.de/page?query#!key=value), die auch für den Browser gültig sind, da Google besser im Rendern von JS wird. Das Crawlen von Escaped-Fragment-URLs wird ab Q2 2018 komplett eingestellt. Das teile Google Ende 2017 mit. HTML-Snapshots müssen demnach nicht mehr zur Verfügung gestellt werden. Zudem teilte Google mit, dass “Abruf wie durch Google” Hashbang-URLs unterstützt.
Grundsätzlich sollte man traditionelle URLs einsetzen. Bei JS-Seiten empfiehlt sich der Einsatz der History API. Das ist dabei die empfohlene Methode (Link). pushState aktualisiert die URL in der Adresszeile bei einer Interaktion auf der Seite. Auf Seiten mit Infinite Scroll lässt sich pushState auch gut einsetzen. Dabei wird beim Scrollen die URL mitakualisiert, sobald der Nutzer auf einen vordefinierten Bereich trifft, den man eigentlich auch als eigene Seite ausspielen könnte. Ein gutes Beispiel dafür ist diese Seite. Statt pushState() wird hier replaceState() verwendet. Mehr zu pushState() und was der Unterschied zu replaceState() ist, kann man hier nachlesen. Insgesamt ist wichtig, dass die URL direkt aufrufbar ist.
Indexierung
Nachdem der Bot ohne Probleme auf JavaScript zugreifen kann, besteht die nächste Herausforderung in der korrekten Indexierung der Inhalte. Google benutzt Headless Browser, um Webseiten besser zu verstehen und um das DOM auszulesen (daher wird etwas JavaScript immer mitausgelesen). Wichtig dabei zu wissen ist, dass der Indexer bzw. Caffeine aus folgenden Elementen besteht:
- Kanonisierung: Sucht und erkennt die Canonical-URL. Hier empfehle ich diesen Artikel über Canonicals.
- Web Rendering Service: Rendert Webseiten wie ein Browser auf Basis der neuesten Chrome-Version (vor dem 07.05.2019 basierte der WRS auf Chrome 41), unterstützt keine Cookies und führt keine Aktionen aus
- PageRanker: Errechnet den PageRank für die URL auf Basis von internen und externen Links und gibt diese Information dem Crawler weiter (hoher PageRank = höhere Crawl-Rate und Crawl-Priorität)
Wichtig ist hier vor allem das Rendering! Beim Rendering kommt Googles Web Rendering Service (WRS) zum Einsatz. Hierzu sollte man folgende Informationen im Hinterkopf behalten:
- HTTP/2 wird noch nicht komplett unterstützt. Da HTTP/2 abwärtskompatibel ist, sollte der Einsatz kein Problem darstellen. Seit November 2020 hat aber Google begonnen auch über HTTP/2 zu crawlen.
- Keine Unterstützung für Web-Socket-Protokoll, IndexedDB und WebSQL-Interfaces für die Datenhaltung im Browser.
- Inhalte, die erst nach dem Zustimmung des Nutzers angezeigt werden, können nicht erfasst werden.
- Inhalte des Local Storage sowie Session Storages werden gelöscht und beim Aufruf einer neuen URL werden keine HTTP-Cookies weitergegeben. Google crawlt also “stateless”, so als ob man jede einzelne URL von neu aufruft.
- Entsprechend werden auch keine Service Worker-Techniken unterstützt.
Wie der Googlebot letztenendlich in der Praxis mit dem Rendering von JavaScript umgeht, hängt auch davon ab welche Rendering-Technik eingesetzt wird. Hierbei unterscheidet man zwischen:
- Client-side Rendering
- Server-side Rendering
Client-side Rendering
Bei dieser Methode wird ein HTML-Dokument vom Server an den Browser (Client) mit reinem HTML-Code gesendet. Sobald der Nutzer mit der Seite interagiert, werden durch JavaScript Inhalte dynamisch im Browser selbst verändert, ohne das die Seite neu geladen werden muss. Hier werden also immer nur die notwendigen Daten durch JS nachgeladen. Wenn der gesamte Webseiten-Inhalt auf diese Weise ausgespielt wird, muss der Googlebot einiges an Arbeit leisten. Das Rendering von JS verbraucht enorme Ressourcen. Hierbei kann es immer wieder passieren, dass Probleme entstehen und im schlimmsten Fall (wenn der Webseiten-Inhalt komplett Client-seitig ausgespielt wird) der Bot nichts als leeres HTML sieht.
Was man zusätzlich beachten sollte, ist die Zeitspanne zwischen dem Crawlen und Indexieren von Client-seitigen JS-Inhalten. Hier können laut Google aufgrund von Ressourcenproblemen mehrere Tage vergehen. Das Ausführen von Javascript benötigt deutlich mehr Rechenleistung als HTML-Seiten. Dadurch geht Google hier in mehreren Schritten und Intervallen vor (Two-wave Indexierung):
- Abruf von serverseitig gerenderten Inhalten
- Initiale Indexierung (= First wave)
- JavaScript-Inhalte in den Rendering-Prozess schieben (siehe Grafik oben)
- Interpretation clientseitiger Code (Rendering)
- Indexierung von weiteren Inhalten bzw. JavaScript-Inhalten (= Second wave)
Falls eine Seite in den Index wandert, kann es sein, dass noch nicht alle Inhalte zu 100% erfasst und verarbeitet wurden. Hier können durch die schrittweise Indexierung Lücken entstehen, die man beim Ranking-Monitoring beachten sollte. Bei besonders aktuellen Inhalten, die schnell in den Index müssen (z.B. News-Seiten), muss dieser Umstand berücksichtigt werden. Wenn hier die JS-Inhalte und -Seiten schneller indexiert werden sollen (also schon in der ersten Indexierungswelle), dann sollte man definitiv auf reine HTML-Seiten zurückgreifen. Alternativ kann man auf eine der veschiedenen serverseitigen Rendering-Techniken zurückgreifen (siehe unten).
Ein weiterer wichtiger Aspekt, der hier berücksichtigt werden muss, ist Folgender: Bei der 2. Indexierung kann es sein, dass der Bot technische SEO-Tags und Canonical nicht mehr berücksichtigt. Dementsprechend ist es besonders wichtig, dass wichtige SEO-Elemente schon bei der initialen Indexierung gerendert und mitgegeben werden.
Beim Client-side Rendering sollte man also 2 Dinge beachten:
- Wichtige Inhalte schon beim initialen Pageload mitschicken
- Wichtige Inhalte nicht von User Events abhängig machen, sondern innerhalb des Load Events ausspielen
Es gibt jedoch hierzu einige Beobachtungen, die auf eine 5-Sekunden-Latenz hinweisen:
- Tests von Screaming Frog haben ergeben, dass der gerenderte Snapshot 5 Sekunden nach dem Load Event seitens Google gemacht wird. Dadurch sollte also der Content innerhalb von 5 Sekunden, nachdem das Load Event abgefeuert wurde, geladen werden, damit die Inhalte indexiert werden können.
- John Müller hat jedoch im Google JavaScript-Forum erwähnt, dass es keinen solchen Timeout gäbe.
- Die Tools “Abruf wie durch Google” in der GSC sowie die PageSpeed Insights von Google berücksichtigen den Timeout von 5 Sekunden. Einfach mal mit diesen Timer von Max Prin testen.
Abgesehen davon sollte man aber auch folgendes beachten: Bing beispielsweise unterstützt JavaScript noch nicht so gut wie Google. Oder auch andere Bots wie der von Facebook haben Probleme mit der Interpretation von JS-Inhalten. Daher sollte man den Einsatz Client-seitiger wichtiger JS-Inhalte hinterfragen.
Beachten muss man auch, dass Google den Rendering-Prozess von JS-Inhalten abbrechen kann, wenn dies für den Bot zu viel Rechenzeit bedeutet.
Server-side Rendering
Die andere, sicherere Form was JavaScript-Indexierung angeht ist das Server-side Rendering. Hier wird die Seite inkl. JavaScript auf dem Server schon vorgerendert (Pre-rendering) und fertig an den Client übergeben. Hier gibt es mehrere Möglichkeiten, wie man die Seite an Browser und Bot ausspielen kann:
- Server-side Rendering für Browser und Bot: Hier bekommen Browser und Bot direkt das gleiche, vorgerenderte Dokument ausgespielt. Alles was mit JavaScript ausgeführt wird, ist schon Server-seitig vorgerendert. So hat es Netflix geschafft die Performance durch Server-seitiges Rendern deutlich zu verbessern (siehe hier).
- Hybrid Rendering: Hierbei handelt es sich um eine Kombination von Server- und Client-seitiges Rendering. Der Server führt das JS aus und sendet es an den Client und Nutzer (das sieht und indexiert der Crawler). Hier wird wichtiger Content für den Index also schon vorgerendert. Zusätzliches JS wird erst nach dem Pageload direkt Client-seitig ausgeführt und dargestellt.
- Dynamic Rendering: Hier werden hier Nutzer und Bot anders behandelt. Während der Nutzer eine Seite bekommt die Client-seitig gerendert werden muss, bekommt der Bot eine schon serverseitig vorgerenderte Seite zugespielt. Auf der Google I/O 2018 betonte Google auch, dass dies nicht als Cloaking bewertet wird. Das für das Rendering viel Rechenleistung benötigt wird, kann dazu ein separater Server genutzt werden. Google hatte anfangs diese Methode empfohlen, mittlerweile ratet Google hiervon ab.
Beim Server-side Rendering ist vor allem auf die Aktualität des Caches zu achten. Im besten Fall wird die vorgerenderte Version sofort mitaktualisiert, wenn sich auf der Seite was ändert. Damit bekommt der Bot immer die neueste Version. Wer Server-seitiges Rendering in Betracht zieht, der kann eigene Lösungen entwickeln oder auf Prerender.io, Renderton, Puppeteer oder bspw. Phantom.js zurückgreifen.
Zusammengefasst heißt das:
- Damit die JavaScript-Inhalte indexiert werden können, müssen diese innerhalb des Load Events geladen werden. Ändert man bspw. den Title durch document.title (ohne Timeout und ohne User-Event-Abhängigkeit), dann kann das Google verarbeiten.
- Inhalte, die durch User Events ausgelöst werden, können Suchmaschinen nicht indexieren.
- Es muss eine indexierbare URL bereitgestellt werden und der Content muss schon serverseitig gerendert werden.
- Bei JavaScript-Seiten müssen die gleichen SEO-Basics wie bei HTML-Seiten berücksichtigt werden (Title, Meta-Description, etc.).
JavaScript-Audit
Nachfolgend findest du Tipps wie du eine JS-Seite händisch und mit Tools analysieren kannst.
Manuelle Prüfung
JavaScript-Inhalte identifizieren
Im ersten Schritt ist es wichtig zu identifizieren, welche Inhalte per JavaScript ausgegeben werden. In Chrome kann man das ganz einfach mit dem Browser-Plugin “Web Developer” machen. Dazu schaltet man JavaScript aus und lädt die Seite neu. In einem zweiten Browserfenster sollte man die gleiche URL mit JavaScript aufrufen. Nun vergleicht man die Seiten miteinander, um feststellen zu können, was per JS ausgeliefert wird. Inhalte, die mit ausgeschalteten JS nicht sichtbar sind, werden mit JS ausgeliefert.
DOM vs. Source Code
Bei JavaScript-Webseiten kann ein Blick in den Quellcode sehr enttäuschend sein. Viele Inhalte werden hier gar nicht zu sehen sein. Der Grund: JavaScript wurde hier noch nicht ausgeführt. Der Quellcode spiegelt das wieder, was vom Server an den Client geschickt wird. Da JavaScript aber clientseitig ausgeführt wird, kann im Quellcode logischerweise kein JS-Inhalt zu sehen sein. Der erste Blick sollte also in den DOM stattfinden, da dort JavaScript schon ausgeführt wurde. Solange der zu indexierende Content im DOM bereitsteht, ist das schon mal ein gutes Signal. Hier sollte man Texte aus dem Browser kopieren und im DOM danach suchen. Wenn der Inhalt dort erscheint, können die Inhalte auch von Google gefunden werden.
Wichtig: Wenn die Seite nicht vollständig gerendert werden kann, dann indexiert Google das initiale HTML ohne dynamische Änderungen.
Was sieht eigentlich Google?
Um zu simulieren, was Google letztendlich sieht, geht man folgendermaßen vor:
- Mit F12 in den DOM wechseln
- Im DOM den HTML-Tag auswählen
- Rechtsklick auf das HTML-Tag, danach zu “Copy” navigieren und dort “Copy OuterHTML” wählen
- Die Kopie in einen Texteditor einfügen
Der kopierte Abschnitt eingefügt in einen Texteditor ist das, was auch Google sieht. Sollten dort die wichtigsten Inhaltselemente zu finden sein, kann man davon ausgehen, dass diese auch vom Googlebot indexiert werden. Hier sollte man beachten, dass dadurch 2 Dokumentversionen entstehen: preDOM Variante (HTML-Quellcode) und postDOM Variante (Gerendertes HTML). Hier ist es wichtig, dass SEO-Tags auf beiden Versionen identisch sind, um Cloaking zu vermeiden. Konkret heißt das: Tags wie Title, Meta-Description, Open Graph Tags und sonstige technischen SEO-Angaben sollten in der HTML- und JS-Version zu finden sein. Zudem muss beachtet werden, dass nicht alle Bots so gut mit JS umgehen können wie Google. Insbesondere sollten die Open Graph Tags für Facebook nicht nur im postDOM, sondern auch im preDOM vorkommen, damit Facebook diese ohne Probleme ausführen kann.
Chrome nutzen
Da Googles Web Rendering Service auf Chrome basiert, sollte man in die Console von Chrome schauen und überprüfen, ob dort JS-Fehlermeldungen angezeigt werden.
Sind die Inhalte innerhalb des Load-Events?
Ein wichtiges Kriterium für die Indexierbarkeit von JS-Inhalten ist, dass der Content innerhalb des Load Events geladen wird. In den Chrome Developer Tools kann man das Abfeuern des Load Events ganz einfach identifizieren. Dazu lädt man die Seite neu und wechselt in den Tab “Network”. In der Timeline sieht man nun die geladenen Ressourcen und 2 senkrechte Striche: einen blauen und einen roten Strich. Der blaue Strich ist das DOMContentLoaded Event und der Rote repräsentiert das Load Event. JavaScript-Content, welches nach diesem Load Event geladen wird, könnte nicht indexiert werden.
User-Event-Content identifizieren
Ob Content von einem User-Event abhängig ist, kann man prüfen, indem man die Chrome Developer Tools aufmacht und sich den DOM anzeigen lässt, während man auf der Seite surft. Wenn man auf wichtige Elemente wie Bildergalerien, aufklappbare Content-Boxen, etc. klickt und der Code im DOM sich live mitändert, sollte man nochmal einen genauen Blick auf den Content werfen. Denn dann ist die Wahrscheinlichkeit hoch, dass dieser abhängig von User-Events ausgespielt wird und somit vermutlich für Bots nicht indexierbar. Um zu prüfen, ob die Inhalte im Index sind oder nicht, kann man den nächsten Schritt ausprobieren.
Nach JS-Inhalten googeln
Um zu überprüfen, ob die Inhalte im Google-Index gelandet sind, sollte man Textblöcke mit “” in den Suchschlitz geben und prüfen, ob Google die Inhalte findet.
Google-Cache überprüfen
Gibt man im Suchschlitz von Google die komplette URL ein und schreibt davor “cache:”, dann gelangt man zur gecachten Google-Version der URL. Hier sollte man einen Abgleich der Seite mit der eigentlichen URL machen. Fehlen Elemente? Gibt es Probleme bei der Darstellung? Findet man hier ein Problem wie beim Fall bei Hulu.com, dann sollte man handeln.
Prüfung mit Tools
Abruf wie durch Google
In der Google Search Console unter “Abruf wie durch Google” kann man die gewünschte Seite zum Rendern schicken. Google sagt dir dann, ob es Crawlingprobleme gibt, denen du dann nachgehen kannst. Falls du keinen Zugriff auf die Seite hast, dann kannst du auch https://technicalseo.com/seo-tools/fetch-render/ verwenden.
Zu beachten ist hier, dass Google mit dem “Abruf wie durch Google”-Tool nur eine Info darüber gibt, ob bez. Rendering technisch alles in Ordnung ist. Falls hier alles passt, heißt es noch lange nicht, dass der Indexierung nichts im Wege steht. Es kann also passieren, dass JS-Inhalte zwar im GSC-Tool gerendert und angezeigt, aber aufgrund anderer Probleme nicht indexiert werden.
Screaming Frog
Der Screaming Frog bietet die Möglichkeit, JavaScript-Inhalte zu crawlen, um sie anschließend zu analysieren. Man erhält einen Screenshot der Seite nach dem Load-Event. Wie das genau funktioniert, wird in diesem Artikel sehr gut beschrieben. Hinweis: Das was man unter dem Tab “Abrufen” bekommt ist das Ergebnis des Crawlers; die Seite, die man zu sehen bekommt unter dem Tab “Abrufen und Rendern” ist das Ergebnis des Indexers.
Zu beachten ist, dass sich der Screaming Frog zwar ähnlich wie der Googlebot verhält, man aber hiermit nicht gewährleisten kann, ob der Googlebot exakt so verfährt. Screaming Frog nutzt die Rendering-Engine “Blink” vom Chromium Project, die sich von der des Googlebots (WRS) unterscheidet.
Searchmetrics Suite
Searchmetrics bietet eine JS-Crawling-Funktion an, welches auf Chrome und PhantomJS basiert.
Developer Tools
Eines der wichtigsten Tools sind die Developer Tools. Hierzu sollte man sich auch mit dem Thema “Breakpoints” beschäftigen.
- Console der Chrome Developer Tools: https://developers.google.com/web/tools/chrome-devtools/console/
- Breakpoints verstehen: https://developers.google.com/web/tools/chrome-devtools/javascript/breakpoints
Google Mobile Friendly Test Tool
Die Analyse von mobilen Webseiten, die JavaScript einsetzen, kann mit dem Google Mobile Friendly Test (https://search.google.com/test/mobile-friendly) durchgeführt werden. Veränderungen, die durch JS gemacht werden, können mit diesem Tool dargestellt werden.
Google Rich Media Tester
Wie beim Google Mobile Friendly Test Tool gilt das Gleiche für den Rich Media Tester, der jedoch nur für Dektop-Testing-Zwecke geeignet ist.
UserAgent-Switcher
Mit diesem Browser-Addon kann geprüft werden wie Googlebot die Seite wahrnimmt. Ruft man eine Seite im Browser normal auf, dann sieht man die Seite so wie es ein Nutzer sehen würde. Schaltet man das JS aus, dann sieht man welche Inhalte per JS ausgespielt werden. Stellt man das Browser-Addon nun auf “Googlebot”, kann man sehen was der Googlebot sieht. Hiermit lässt sich auch sehen, ob ein Server-seitiges Rendering eingesetzt wird.
4 Sichtweisen
Da mittlerweile der mobile Traffic eine zentrale Rolle spielt, sollten JS-Audits unter Berücksichtigung der folgenden 4 Sichtweisen durchgeführt werden:
- JS-Audit aus Mobile-Sicht mit JavaScript-Rendering
- JS-Audit aus Mobile-Sicht ohne JavaScript-Rendering
- JS-Audit aus Desktop-Sicht mit JavaScript-Rendering
- JS-Audit aus Desktop-Sicht ohne JavaScript-Rendering
Weitere Informationen zum Thema JavaScript und SEO
Isomorphic JavaScript
Bei Isomorphic JavaScript handelt es sich um eine Applikation, die JavaScript-Code Client- und auch Server-seitig rendern kann. Der gleiche JS-Code wird von Client und Server ausgeführt bzw. geteilt. Dabei wird ein schon vorgerenderte Code an den Client geschickt. Nutzer und Bots sehen also die Inhalte. Während der Bot den Inhalt indexieren kann, werden dem Nutzer trotzdem weiterhin dynamische Inhalte dargeboten. Aktueller Nachteil ist, dass nicht alle JavaScript-Frameworks den Ansatz des Isomorphic JavaScript unterstützen.
Angular Universal und SEO
Bei Angular handelt es sich um ein SPA-Framework (Single Page Application). Damit lassen sich Webseiten erstellen, die innerhalb des Browsers arbeiten. Initial wird ein HTML ausgeliefert. Content, Style und weitere Elemente werden dann direkt im Client verarbeitet. Dies stoßt natürlich auf SEO-Probleme, was Crawling und Indexierung angeht. Um dies zu lösen gibt es jedoch eine Rendering-Library, die Server-seitig funktioniert: Angular Universal. Wie diese Technik genau funktioniert, kann man auf der offiziellen Webseite nachlesen: https://angular.io/guide/universal.
Fix Search-related JavaScript problems
In einem Dokument namens “Fix Search-related JavaScript problems” hat Google Tipps veröffentlicht wie man bei Problemen mit JavaScript-Seiten vorgehen kann. Folgende Schritte sollten dazu umgesetzt werden:
- Die betreffende Seite sollte zunächst mit dem “Google Mobile Friendly Test Tool” und “URL Inspection Tool” in der Search Console geprüft werden. Dort erhält man alle relevanten Probleme und Informationen. Optional empfiehlt Google JavaScript-Fehler zu sammeln und auszuwerten. Dazu stellt Google einen Code bereit (siehe Link).
- Der Googlebot lehnt Permission Requests ab. Beispiel: Wenn eine Seite Zugriff auf die Kamera haben möchte, kann Google damit nichts anfangen. Man sollte den Zugang zur Seite auch ohne die Erteilung spezieller Einwilligungen erlauben.
- Local Storage, Session Storage und HTTP-Cookies werden vom Googlebot nicht unterstützt. Heißt: Falls die Anzeige des Contents auf diesen Techniken basiert, dann kann dies Google nicht sehen, da sich der Bot den Status zwischen 2 Seitenaufrufen nicht merkt.
- Man sollte Feature Detection für kritische APIs und Polyfills als Fallback anbieten.
- Webkomponenten sollte Suchmaschinen-freundlich sein: Shadow DOM um Implementierungsdetails zu verbergen und Light DOM für Content verwenden.
- Nachdem alle Punkte geprüft und ggf. behoben worden sind sollte man die Seite wieder mit dem “Google Mobile Friendly Test Tool” und “URL Inspection Tool” in der Search Console testen.
JavaScript-Redirects
In der Google Webmasters YouTube-Episode “Client-side JS Redirects: Can Googlebot Detect Them?” erklärte Google: “We support JavaScript redirects of different types and follow them similar to how we’d follow server-side redirects.”
In einem Video erklärt Google weitere Details zu JS-Redirects. Wie weiter oben erwähnt müsse man bei AJAX-Seiten keine besonderen Vorkehrungen bei Google treffen. Hashbang-URLs (“#!”) könnte der Bot nun crawlen und verarbeiten. Wer aber Redirects von Hashbang-URLs zu “normalen” URLs setzen möchte, sollte dies mit JS-Redirects vornehmen. Crawlt Google eine Hashbang-URL, könnte der Bot den clientseitigen Redirects dadurch entdecken und verarbeiten können. Serverseitige Redirects würden hier nicht funktionieren, da der URL-Teil nach “#” nicht an der Server geschickt wird. Dieser Teil wird nur vom Browser erkannt.
JavaScript und noindex
JavaScript ermöglicht das nachträgliche Ändern von Angaben im HTML. So könnte man auch Meta-Tags, die für SEO genutzt werden, nachträglich ändern. Dazu gehört auch die Anweisung “noindex”. Hier gibt es 2 Fälle:
- Im HTML ist ein “index”, welches durch JavaScript auf “noindex” geändert wird.
- Im HTML ist ein “noindex”, welche durch JavaScript auf “index” geändert wird.
Der erste Fall stellt für Google kein Problem dar. Hier muss man nur im Hinterkopf behalten, dass die Seite eventuell zunächst indexiert wird. Erst wenn – einige Zeit später – Google das JavaScript ausführt, wird die Seite aus dem Index genommen. Problematisch kann der zweite Fall sein. Wenn eine Seite initial im HTML mit einem “noindex” vermerkt ist, dann kann dies dazu führen, dass Google die weitere Verarbeitung der Seite abbricht. Durch den Abbruch kann der Bot das “index” nicht mehr wahrnehmen und die Seite bleibt aus dem Index. Google hat diesen Aspekt in der Dokumentation zu JavaScript und SEO mitaufgenommen.
Offizielle Statements seitens Google zu JavaScript
- 2015 kündigte Google an, dass man nun in der Lage sei, Webseiten wie ein moderner Browser zu verstehen. Aus diesem Grund sollte man CSS- und JS-Dateien nicht per robots.txt aussperren.
- Google hat ein gutes Verständnis für das Crawlen von JS-Inhalten.
- In einem Google+ Post hat John Müller zahlreiche Tipps für den Einsatz von JavaScript gegeben (mehr dazu auch weiter unten).
SEO-JavaScript-Tests in der Praxis
Nachfolgend findest du einige SEO-Praxis-Test zum Thema JavaScript.
Test 1: JavaScript Frameworks
Eckpunkte
- Durchgeführt von Bartosz Goralewicz
- Link zum Test
- Szenario: Die Webseite http://jsseo.expert/ wurde gebaut, um herauszufinden, wie Google mit verschiedenen JavaScript Frameworks umgeht
Auf den Punkt gebracht
- Für Google macht es einen Unterschied, ob man JavaScript Inline, extern oder gebündelt verwendet
- Der Content im Google-Cache bedeutet nicht automatisch, dass dieser auch im Index ist
Details
Bei diesem Test wurde die Webseite http://jsseo.expert/ erstellt. Über die Startseite gelangt man auf verschiedene Unterseiten mit Content, welche mit verschiedenen JavaScript-Frameworks ausgespielt werden. Innerhalb des Contents wurden auch interne Links platziert, um zu sehen, ob Google diesen folgen kann. Um das Testergebnis zu evaluieren, wurden folgende Fragen beantwortet:
- Wird die Seite mit dem “Abruf wie durch Google” Tool in der GSC korrekt gerendert?
- Wurde die URL von Google indexiert?
- Ist der Content im Google Cache sichtbar?
- Sind die Links im Google Cache sichtbar?
- Gibt die Google-Suche nach dem JS-Content diesen in den SERPs aus?
- Wurden die intern verlinkten Seiten (mit JS-Links) gecrawlt?
Das Ganze wurde dann noch mit den unterschiedlichen Frameworks getestet, mit folgenden Ergebnissen:
- jQuery: Das “Abruf wie durch Google” Tool konnte Inline geladenen Code normal rendern. Bei extern eingebundenen jQuery und jQuery-Code, der über Ajax-Calls läuft, gab es ebenfalls keine Probleme. In allen Fällen wurde die URL und der Content indexiert. Interne Links konnte der Googlebot nur bei inline und über Ajax-Calls eingesetzen jQuery crawlen. Links, die über eine externe Datei eingebunden wurden, konnte der Googlebot nicht ausführen.
- React: Auch hier hatte der Googlebot keine Probleme beim Rendern der Seite über die GSC sowie bei der Indexierung der URL und des Contents. Wie bei jQuery konnte auch hier Google internen Links folgen, die über Inline-Code eingebunden waren. Links, die über eine externe React-Datei eingebunden wurden, konnte der Bot nicht finden.
- Plain JavaScript: Gleiches Bild wie bei React.
- AngularJS: Die Version 1 konnte Google korrekt Rendern (über GSC) und die URL und den Content indexieren. Interne Links konnte der Bot nicht finden. Bei der Version 2 und Version 2 Bundled hatte Google Probleme beim Rendern über der GSC, konnte den Content nicht indexieren und nicht den internen Links folgen. Lediglich die Indexierung der URL klappte.
Wie man sieht ist kein JavaScript-Framework von Grund auf optimal für SEO. Beim Einsatz bedarf es einer intensiven SEO-Begleitung. Überraschend bei diesem Test ist, dass AngluarJS – ein von Google entwickeltes Framework – am schlechtesten abgeschnitten hat. Man muss jedoch bedenken, das AngularJS clientseitig ausgeführt wird, weshalb der Googlebot hier seine Probleme hat.
Test 2: JavaScript-Crawling
Eckpunkte
- Durchgeführt von Adam Audette
- Link zum Test
- Szenario: Verschiedene JavaScript-Funktionen wurden auf einer Seite eingebaut, um zu testen wie Google bspw. mit JS-Links oder -Content umgeht
Auf den Punkt gebracht
- Google folgt und akzeptiert JavaScript-Weiterleitungen und -Links
- Dynamisch generierter Content und SEO-Tags wurden vom Bot erkannt und richtig verarbeitet
- Das Nofollow-Attribut wurde im HTML-Code erkannt und verarbeitet, im DOM nicht
Details
JavaScript-Redirects wurden mit der Funktion window.location getestet. Diese Redirects wurden von Google gefolgt und als 301 interpretiert. Die alte URL wurde durch die neue im Google-Index ersetzt. Auch eine gut-rankende URL wurde per JavaScript weitergeleitet. Die neue URL konnte die gleiche Position erzielen wie die alte URL. Grundsätzlich sagt Google zu JavaScript-Weiterleitungen:
“Die Verwendung von JavaScript zur Weiterleitung von Nutzern kann durchaus legitim sein. Wenn Sie Nutzer beispielsweise zu einer internen Seite weiterleiten, sobald sie angemeldet sind, können Sie dazu JavaScript verwenden. Wenn Sie JavaScript oder andere Weiterleitungsmethoden auf Ihrer Website überprüfen, um sich zu vergewissern, dass diese unseren Richtlinien entsprechen, berücksichtigen Sie die zugrunde liegende Absicht. Beim Verschieben Ihrer Website eignen sich 301-Weiterleitungen am besten. Sie können jedoch zu diesem Zweck auch eine JavaScript-Weiterleitung verwenden, wenn Sie nicht auf den Server Ihrer Website zugreifen können.” (Quelle)
Bez. internen JS-Links wurden unterschiedliche Typen getestet. Dropdown-Menülinks, Standard-JS-Links (z.B. onClick, javascript:window.location, javascript:openlink(), etc.), Links nachdem onmousedown sowie onmouseout abgefeuert wurden und verkettete Links wurden alle gecrawlt und die URLs dahinter wurden indexiert.
Dynamisch generierter Content (Text, Bilder, Links und Navigation) innerhalb des HTML- und/oder JavaScript-Codes (externe JS-Datei) wurde in beiden Fällen gecrawlt und indexiert.
Dynamisch generierte SEO-Tags (Title, Meta-Description, Meta-Robots und Canonicals) wurden vom Bot erkannt, gecrawlt und richtig verarbeitet.
Der letzte Test bezog sich auf das Nofollow-Attribut. Ergebnis: Das Nofollow-Attribut im HTML-Code wurde respektiert; ein Nofollow-Attribut im DOM nicht.
Test 3: JavaScript-Indexierung
Eckpunkte
- Durchgeführt von Michael Göpfert
- Link zum Test
- Szenario: Auf einer HTML-Seite wurden Inhalte per JavaScript auf verschiedene Arten eingefügt und über die GSC zur Indexierung geschickt, um zu überprüfen, wie Google mit den JavaScript-Inhalten umgeht
Auf den Punkt gebracht
- Internes JavaScript konnte Google korrekt interpretieren und indexieren
- Externes JavaScript konnte von Google ebenfalls fast korrekt interpretiert und indexiert werden
- Per robots.txt gesperrtes JavaScript berücksichtigt der Bot nicht
Details
Auf der HTML-Seite (https://www.michaelgoepfert.de/js-test/) wurden insgesamt 7 Container erstellt, die auf unterschiedliche Arten JavaScript-Inhalte ausliefern:
- Die ersten 2 Container werden per internem JavaScript ausgeführt: Einmal nach dem DOMContentLoaded (wird abgefeuert sobald das DOM zur Verfügung steht) und einmal nach dem Load Event.
- Weitere 4 Container werden per externem JavaScript auf folgende Arten ausgeführt: Nach dem DOMContentLoaded, nach dem Event Load, nach dem Event Load, jedoch wird in diesem Fall die JS-Datei per robots.txt gesperrt und einmal per 3 Sekunden Timeout.
- Der letzte Container-Inhalt wird per asynchronem JavaScript eingebunden.
Danach wurde die Seite per Google Search Console eingereicht. Alle Container-Inhalte – bis auf die JS-Datei die per robots.txt gesperrt war – wurden korrekt ausgegeben. Ein Blick in den Google-Cache zeigte jedoch, dass nur die internen JS-Dateien aus dem Head korrekt interpretiert werden. Nachdem aber die Dateien über die GSC zur Indexierung überreicht wurden, konnten auch die restlichen Skripte – bis auf das asynchrone JavaScript – dargestellt werden. Auch rankten fast alle Inhalte, bis auf die per robots.txt gesperrte Datei.